VGG16: Deep Neural Network for Image Classification¶
05/31/2019
- Oxford Visual Geometry Group (VGG)
VGG16 Deep Convolutional Neural Network (Deep CNN)¶
- Keras VGG-16: 16 trainable layers (13 convolutional, plus 3 MLP classifier layers)
- 138.4 million parameters (Total params: 138,357,544)
- Convolutional base only (13 layers) - Total params: 14,714,688
- Pre-trained on ImageNet classification - 1,000 output image classes
- Main arguments: include_top=True/False, input_shape=(224, 224, 3) (optional)
- Final feature map output shape (7, 7, 512)
VGG16 and VGG19 developed by the Oxford Visual Geometry Group (VGG), 2012 - 2014. ImageNet performance (ICLR 2015):
- Top-1 accuracy of 75/2% (24.8 error rate)
- Top-5 accuracy of 92.5% (7.5% error rate)
Very Deep Convolutional Networks for Large-Scale Image Recognition, Karen Simonyan & Andrew Zisserman, Visual Geometry Group, Department of Engineering Science, University of Oxford, ICLR 2015. (https://arxiv.org/abs/1409.1556)
VGG16 ImageNet image classification¶
VGG16 was state of the art in 2014. Newer deep network architectures, with far fewer parameters, and training and inference time requirements, outperform VGG16 in 2019 on ImageNet and other tasks.
accuracies (document values, refs):
- Inception V3
- Xception
- ResNet (2015)
- SSD (2018)
- YOLOv3 (11/2018)
- EfficientNet (05/2019)
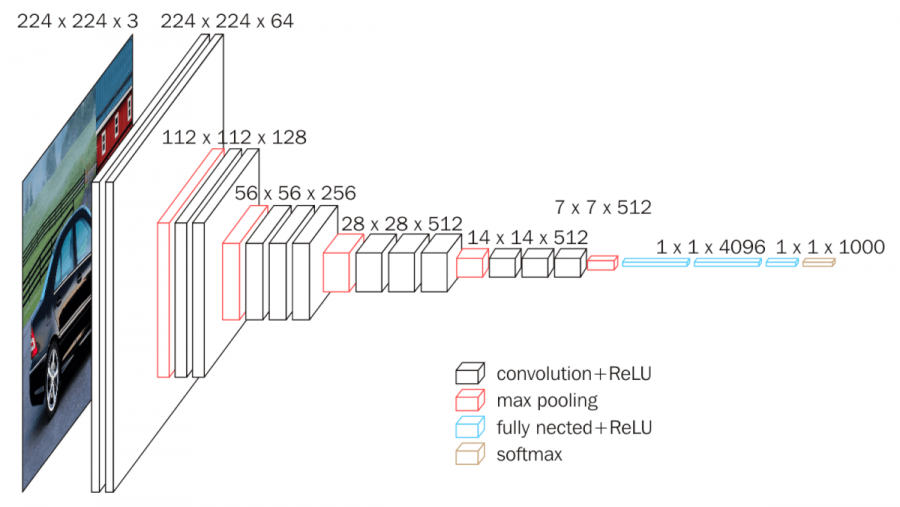
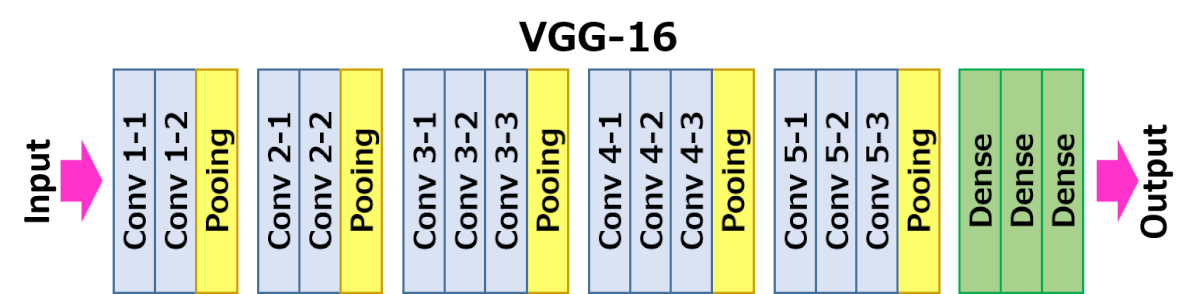
VGG-16 Architecture¶
VGG-16 has 13 Conv2D layers, 5 MaxPooling2D, 1 flatten, and 3 output classifier layers (Dense):
(2) Conv2D-1 - Conv2D-2 - MaxPooling2D
(2) Conv2D-1 - Conv2D-2 - MaxPooling2D
(3) Conv2D-1 - Conv2D-2 - Conv2D-3 - MaxPooling2D
(3) Conv2D-1 - Conv2D-2 - Conv2D-3 - MaxPooling2D
(3) Conv2D-1 - Conv2D-2 - Conv2D-3 - MaxPooling2D
flatten (Flatten)
fc1 (Dense) - fc2 (Dense) - predictions (Dense)
Other pre-trained CNN models part of keras.applications:
- VGG-16, VGG-19, ResNet-50, Inception, Inception-ResNet, Xception.
# Using TF 1.13.1; TF 2.0.0-alpha0 not compatible
import numpy as np
import os
import cv2
from datetime import datetime
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import optimizers
from tensorflow.keras import backend as K
from tensorflow.keras.preprocessing import image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
print("TensorFlow:", tf.__version__, "Keras:", keras.__version__)
# VGG16 Full Pre-Trained Network (Keras)
from tensorflow.keras.applications import VGG16
from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions
vgg16_full = VGG16(weights='imagenet', include_top=True, input_shape=(224, 224, 3))
VGG16 weights (553 MB size):¶
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5
553467904/553467096 [==============================] - 36s
553 MB VGG16 model download the first time VGG16() is called from Keras.
vgg16_full.summary()
VGG16 input/output tensors and classifier¶
VGG16 convolutional base input tensor (images): ( _, 224, 224, 3)¶
input_1 (InputLayer) (None, 224, 224, 3) 0
VGG16 convolutional base output tensor: ( _, 7, 7, 512)¶
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
VGG16 output classifier input tensor (features): ( _, 7, 7, 512)¶
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 1000) 4097000 VGG16 Architecture (ImageNet classifier)¶
# vgg16_full
print("VGG16 Layers")
layer = vgg16_full.layers[0]
for layer in vgg16_full.layers:
print(layer)
# Load some test images for predictions with VGG16
image_dir = './data/images/'
image_fns = ['african_elephant.jpg', 'indian_elephant.jpg', 'cat.1.jpg', 'cat.2.jpg',
'dog.66.jpg', 'dog.166.jpg']
image_fns_wrong = ['african_elephant.jpg', 'indian_elephant.jpg', 'cat.1.jpg', 'cat.2.jpg',
'dog.66.jpg', 'dog.166.jpg', 'giraffe.jpg', 'man.jpg', 'woman.jpg']
image_fns_mix = ['african_elephant.jpg',
'african_elephant_people.jpg', 'african_elephant_jeep.jpg',
'dog_bike_truck.jpg', 'giraffe_zebra.jpg',
'person_horse_dog.jpg', 'man_woman.jpg']
image_fns_art = ['art/dama_sentada.jpg', 'art/scream.jpg']
# PIL images resized to 224x224
# Alternatives: resize to smaller dimension (width, height), crop center instead
images = []
for image_fn in image_fns_mix:
img = image.load_img(image_dir+image_fn, target_size=(224, 224))
img_arr = np.array(img)
images.append(img_arr)
images_arr = np.array(images) # /255
images_pre = preprocess_input(images_arr * 1)
print("images_arr.shape:", images_arr.shape)
# VGG16 preprocessed images reshaped and streched to (224, 224, 3)
# image, preprocessed images_pre
print("images[0].shape:", images[0].shape, end=' - ')
print("images_pre.shape:", images_pre.shape)
plt.figure(figsize=(18,10))
plt.subplot(121)
plt.imshow(images[0])
plt.subplot(122)
plt.imshow(images[1])
plt.show();

# Predict classes for loaded images
predictions = vgg16_full.predict(images_pre, steps=1)
print("shape:", predictions.shape)
print("argmax[0]:", np.argmax(predictions[0]))
print(predictions)
# Top 5 predictions for images[0]
top_5 = tf.keras.applications.vgg16.decode_predictions(predictions, top=5)
for class_id, name, y_proba in top_5[0]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()
# Top 5 predictions for all images
top_5 = tf.keras.applications.vgg16.decode_predictions(predictions, top=5)
for image_index in range(len(images)):
print("Image {}".format(image_index))
plt.imshow(images[image_index])
plt.show()
for class_id, name, y_proba in top_5[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()







# Another image (painting)
image_path = image_dir+image_fns_art[0]
print("image_path:", image_path)
img = image.load_img(image_path, target_size=(224, 224))
img_arr = np.array(img)
images = np.expand_dims(img_arr, axis=0)
images_pre = preprocess_input(images)
plt.figure(figsize=(6,6))
plt.imshow(img)
plt.show()
# Print object predictions
predictions = vgg16_full.predict(images_pre, steps=1)
for class_id, name, y_proba in top_5[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))

VGG16 Transfer learning: Custom output classifier¶
Using VGG16 convolutional base + Dense 25088 x 256 x 1 classifier¶
- 13 convolutional layers from VGG16
- 2 fully-connected layers of binary output classifier
- Trainable params: 21,137,729 (14,714,688 base; 6,423,041 classifier)
- Image input shape does not affect size of the network, only size of output feature tensor
# Import VGG16 convolutional base, with original input shape (224, 224, 3)
K.clear_session()
vgg16_base_224 = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
VGG16 base (59 MB)¶
Initial Download:
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58892288/58889256 [==============================] - 7s
59 MB model download the first time VGG16 base is called from Keras.
Model: "vgg16_base_224"¶
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
...
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
Output shape¶
vgg16_base_224.output_shape: ( _, 7, 7, 512)vgg16_base_224.summary()
Kaggle image classification challenge: sample dogs vs. cats¶
- Kaggle competition URL: https://kaggle.com/c/dogs-vs-cats
- dogs vs. cats data: https://kaggle.com/c/dogs-vs-cats/data
Based on Deep Learning with Python, François Chollet, 2017,
Manning Publications, (Chapter 5)
https://www.amazon.com/Deep-Learning-Python-Francois-Chollet/dp/1617294438
# Sample kaggle/dogs-vs-cats images
kaggle_dogcats_dir = '/Users/nelson/dev/datasets/cv/kaggle/dogs-vs-cats_small/'
train_dir = os.path.join(kaggle_dogcats_dir, 'train/')
dog_fns = os.listdir(train_dir + 'dogs')
cat_fns = os.listdir(train_dir + 'cats')
dog_img = cv2.imread(train_dir + 'dogs/' + dog_fns[0])
cat_img = cv2.imread(train_dir + 'cats/' + cat_fns[0])
print("dog_img.shape:", dog_img.shape, end=' - ')
print("cat_img.shape:", cat_img.shape)
print("images will be reshaped to (224, 224, 3)")
plt.figure(figsize=(12,10))
plt.subplot(121)
plt.imshow(dog_img)
plt.subplot(122)
plt.imshow(cat_img)
plt.show();

MLP Dense 25088 x 256 x 1 output classifier for VGG16 top layer¶
MLP Dense 25088 x 256 x 1 binary classifier - model.summary:
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 256) 6422784
_________________________________________________________________
dropout_3 (Dropout) (None, 256) 0
_________________________________________________________________
dense_7 (Dense) (None, 1) 257
=================================================================
Total params: 6,423,041
Trainable params: 6,423,041
Non-trainable params: 0
_________________________________________________________________# MLP Dense 8192 x 256 x 1 output classifier for VGG16 top layer
vgg16_features_shape = vgg16_base_224.output_shape[1:]
print("vgg16_features_shape:", vgg16_features_shape)
print("mlp_input_shape:", np.product(vgg16_features_shape))
mlp_input_dim = np.product(vgg16_features_shape) # 7*7*512 = 25088
mlp = models.Sequential()
mlp.add(layers.Dense(256, activation='relu', input_dim=mlp_input_dim))
mlp.add(layers.Dropout(0.5))
mlp.add(layers.Dense(1, activation='sigmoid'))
mlp.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy', metrics=['acc'])
# MLP summary
mlp.summary()
VGG16 Image Preprocessing¶
Preprocess image dataset with vgg16_base pretrained VGG16 model head.
- Input image size: (224, 224, 3)
- Output feature size: (7, 7, 512)
# Image feature extraction
# kaggle_dogcats_dir = '/Users/nelson/dev/datasets/cv/kaggle/dogs-vs-cats_small'
train_dir = os.path.join(kaggle_dogcats_dir, 'train')
validation_dir = os.path.join(kaggle_dogcats_dir, 'validation')
test_dir = os.path.join(kaggle_dogcats_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
# features = np.zeros(shape=(sample_count, 4, 4, 512))
features = np.zeros(shape=(sample_count, 7, 7, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary') # TBD: ImageDataGenerator, make multinomial
i = 0
for inputs_batch, labels_batch in generator:
features_batch = vgg16_base_224.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
return features, labels
# Timing
start_time = datetime.now()
print("VGG16 conv_base Start:", str(start_time))
train_features, train_labels = extract_features(train_dir, 2000)
train_time = datetime.now()
print("Training features done:", str(train_time))
validation_features, validation_labels = extract_features(validation_dir, 1000)
val_time = datetime.now()
print("Validation features done:", str(val_time))
test_features, test_labels = extract_features(test_dir, 1000)
# Time
end_time = datetime.now()
print("Test features done/End:", str(end_time))
print("VGG16 conv_base Total seconds:", str(end_time-start_time))
str(start_time), str(end_time), (end_time-start_time)
VGG16 Base: Time for feature extraction (CPU)¶
- 4,000 total images (2,000 training, 1,000 validation, 1,000 test)
- 224 x 224 x 3 resolutiion
Total time: 15:51 minutes (1010 seconds) - 0.25 s/image (on CPU, i7 quad-core)
# Features shape: VGG16 conv_base output feature map shape (7, 7, 512)
print("train_features.shape:", train_features.shape)
print("validation_features.shape:", validation_features.shape)
print("test_features.shape:", test_features.shape)
# Reshape features: extracted features from (samples, 7, 7, 512) to (samples, 25088)
train_features = np.reshape(train_features, (2000, 7*7*512))
validation_features = np.reshape(validation_features, (1000, 7*7*512))
test_features = np.reshape(test_features, (1000, 7*7*512))
print("MLP reshaped train_features.shape:", train_features.shape)
Output MLP Classifier Training and Evaluation¶
Train output MLP Classifier with pre-processed image from VGG16 model head.
- Classifier input feature size: (4, 4, 512)
- Output: MLP sigmoid output Dense layer
# Time
start_time = datetime.now()
history = mlp.fit(train_features, train_labels, epochs=20, batch_size=20,
validation_data=(validation_features, validation_labels))
# Time
end_time = datetime.now()
print("MLP Dense 25088*256*1 - Total seconds:", str(end_time-start_time))
MLP output classifier: Time for classification (CPU)¶
- 2,000 training images; 1,000 validation images
- 25,088 (7x7x512) input feature vector
- Binary output, epochs=20, batch_size=20
Total time: 1:06 minutes (66 seconds)
# Visualize accuracy, loss on training and validation sets
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
accuracy_template = "Epochs: {}, Best acc: {}, Best val_acc: {}"
print(accuracy_template.format(len(epochs), np.max(acc), np.max(val_acc)))
plt.figure(figsize=(18,5))
plt.subplot(121)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(122)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()

# Model evaluation
print("test_features.shape:", test_features.shape)
test_loss, test_acc = mlp.evaluate(test_features, test_labels, steps=50)
print('vgg16_model/custom output MLP - test acc:', test_acc)